
Storing Sortable Items in a Relational Database
Hey there! How’s it going? Last week, while working on Bezier, I ran into a problem I hadn’t encountered before. After some thought, I arrived at a solution that I want to share today, hoping it helps others facing the same challenge.
Problem
Imagine you have a drag-and-drop sortable list, like the one below, where you can arrange items in any order you prefer.

Here’s the catch: we’re using Cloudflare D1 for storage. This means we need to solve this using a relational database (SQLite) while minimizing read/write operations to keep performance high and costs low.
Even though the app is offline-first, real-time synchronization is critical. Changes need to be pushed to the database the moment they happen.
Given these constraints, have you thought of a solution yet?
The First Solution
The first solution was somewhat trivial: just add a position field ranging from 0 to N. If you want to move element j to position i, you update all elements in the range [min(i, j), max(i, j)) to reflect their new positions.
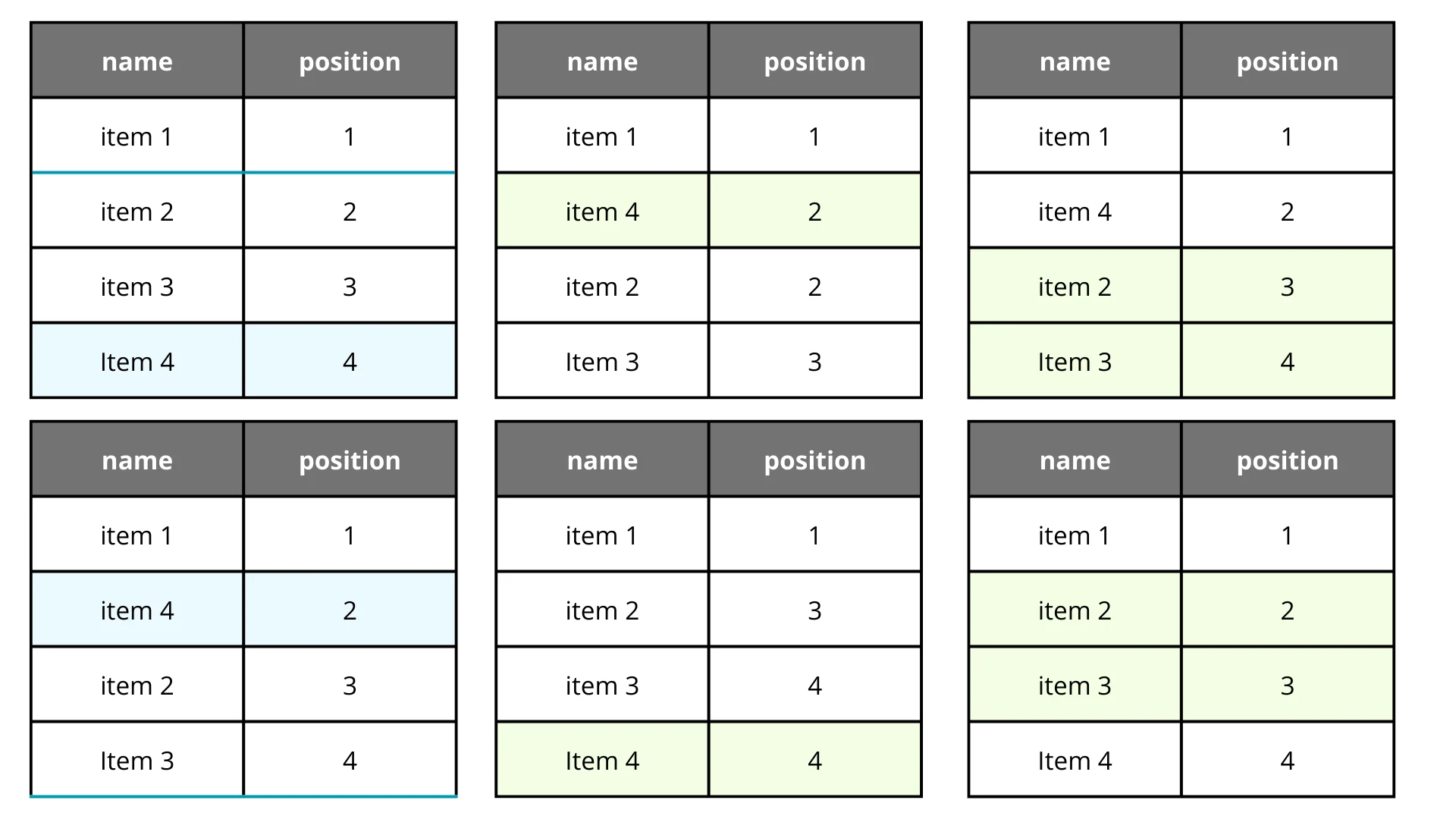
Nothing out of the ordinary, it’s a classic insertion algorithm. The problem? For every single change, we have to update multiple records. This gets expensive (and slow) very quickly.
The Linked List Solution
What about a linked list? You create next and prev cursors pointing to IDs. To reorder, you only need to update a few records to establish the new sequence.
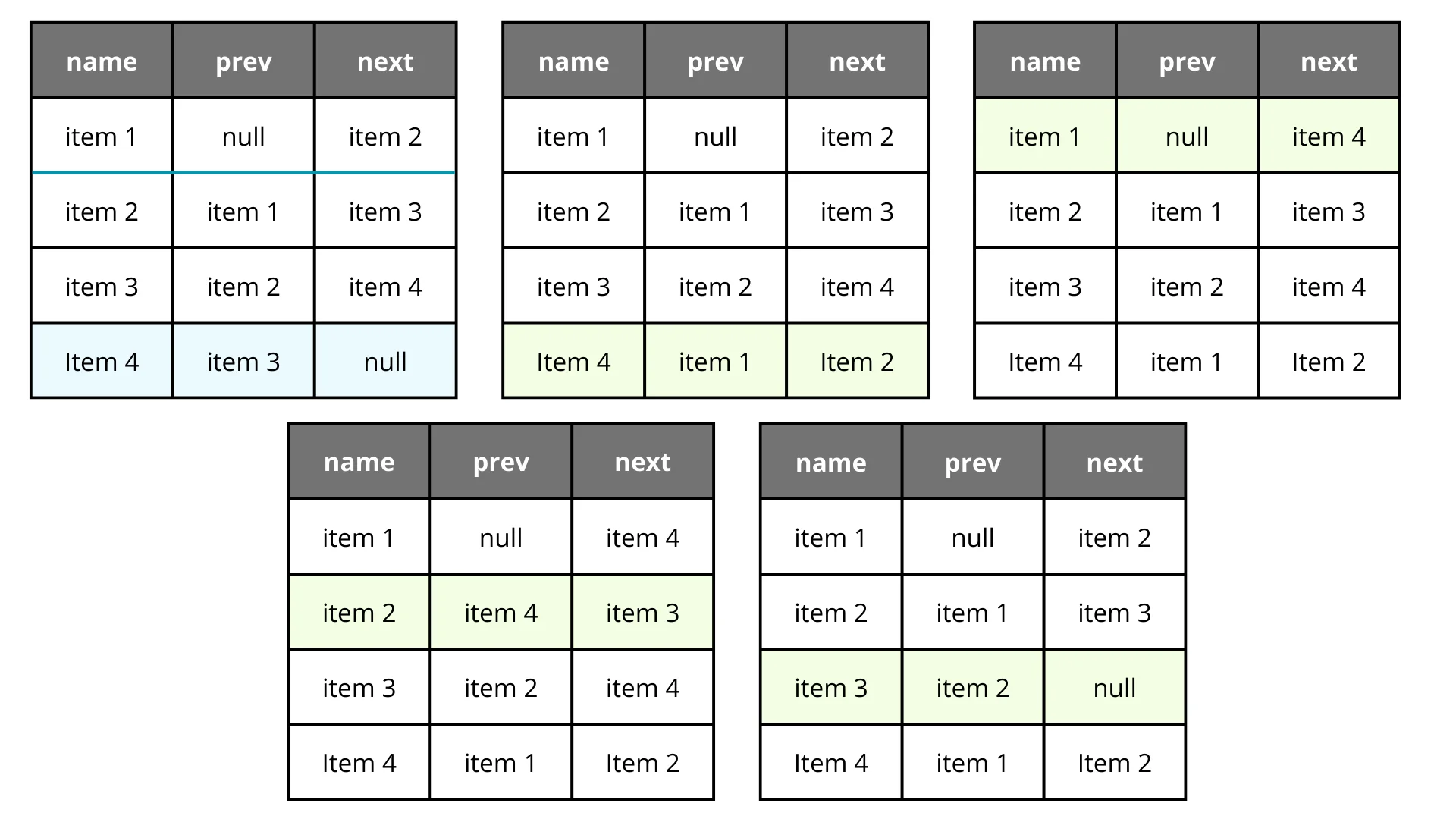
It’s definitely better and more predictable than the array shift approach, but it still touches multiple rows. It’s also harder to query efficiently and can lead to data integrity nightmares in concurrent environments.
The JSON Field
I see. The problem feels like it’s SQL itself. If we used a Document or Graph database, this might be easier. So, why not use a JSON field to store the items instead of normalized rows?

This is a valid solution, but it doesn’t work for my use case. My items have complex relations and require specific queries that would be painful inside a JSON blob. I can’t sacrifice that relational integrity. Still, if no better solution existed, I might have settled for this.
The JSON Order Field
Okay. If relationships matter, why not decouple the order from the model? We could create a unified “order” field that simply contains an array of IDs in their rendering sequence.
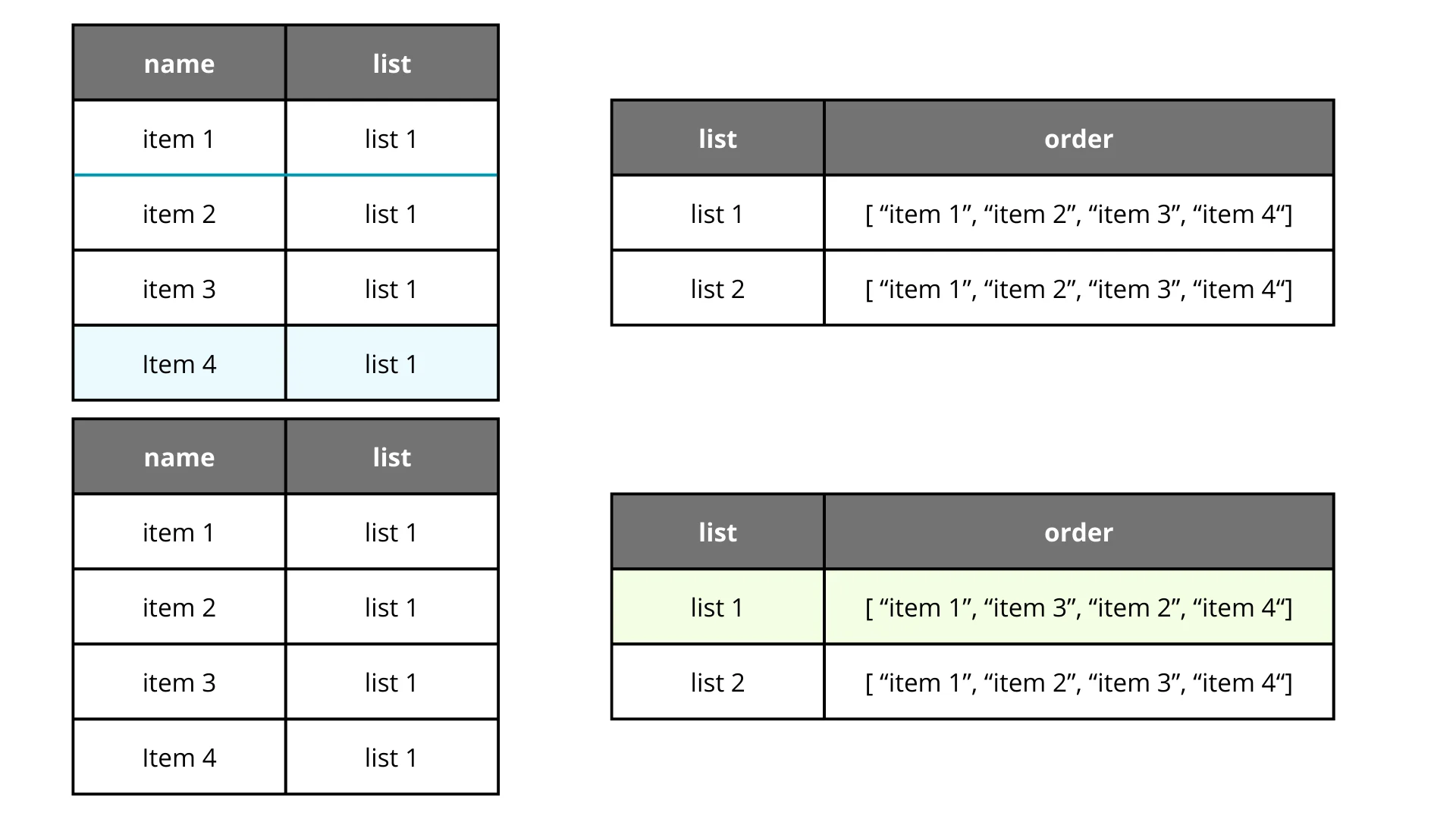
This makes sense. It solves the problem and only updates a single field. Perfect, right? Well… I believe there are no perfect solutions, only optimal trade-offs. This might work for simple lists, but what about nested items? It complicates things quickly. I didn’t feel comfortable with this approach, but it’s worth mentioning if your needs are simpler.
The Integer Gap Solution
Let’s circle back to the first solution. The issue was updating massive ranges for a single move. But what if we didn’t use sequential integers (1, 2, 3)? What if we left gaps?
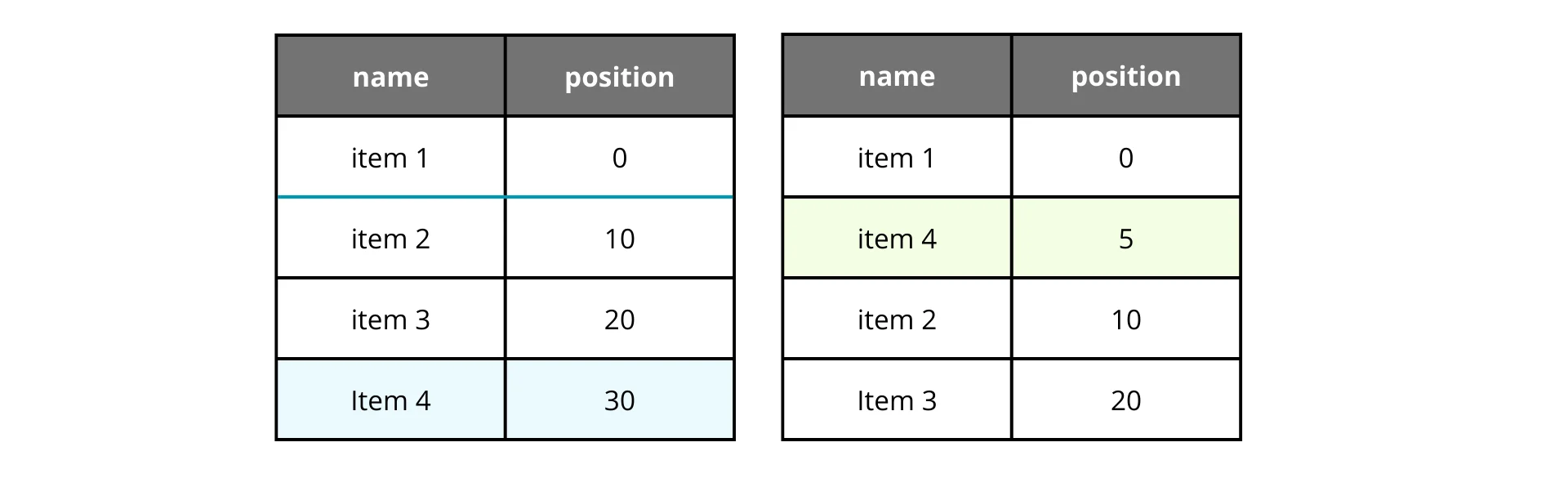
If we want to move an item, we calculate the midpoint between its new neighbors. It works like a charm, until it doesn’t. Let’s say we move item 2 back to the second position repeatedly.
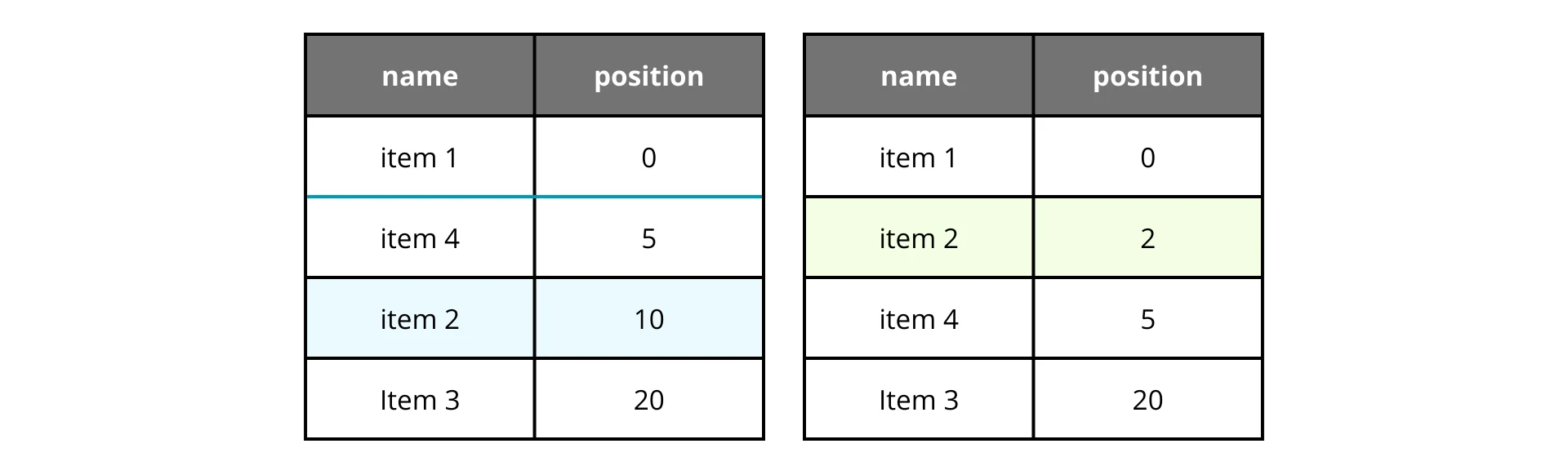
See that? After moving item 2 again, the available gap shrinks drastically. Even starting with a gap of 10, we quickly run out of space to insert new items.
The Real Gap Solution
This happens because integers are discrete, there’s nothing between 0 and 1. But real numbers are infinite. Why not use floats?
Because it doesn’t solve the problem, it just delays it. You might get 10-50 more sorts before hitting the limit of floating-point precision. Mathematical precision is infinite; 64-bit floats are not. We need a better way.
The Lexorank Solution
Who said we have to use numbers? Why not use strings? We can use alphanumeric characters and sort them lexicographically.
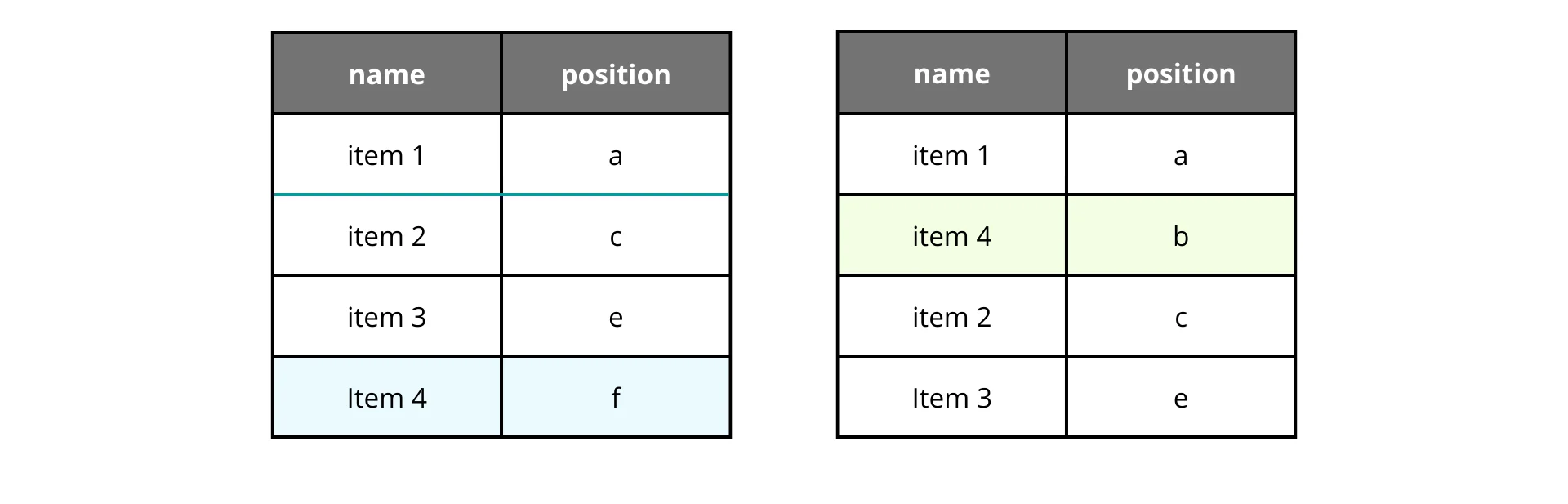
It works, but using a single character has the same limitations as integers. The “gap” between “A” and “B” is fixed. We need more granularity.
This is where it gets interesting. If we use strings, we can append characters to create new “midpoints.” “A” comes before “B”, but “AA” comes between “A” and “B” if we treat them essentially as fractions.
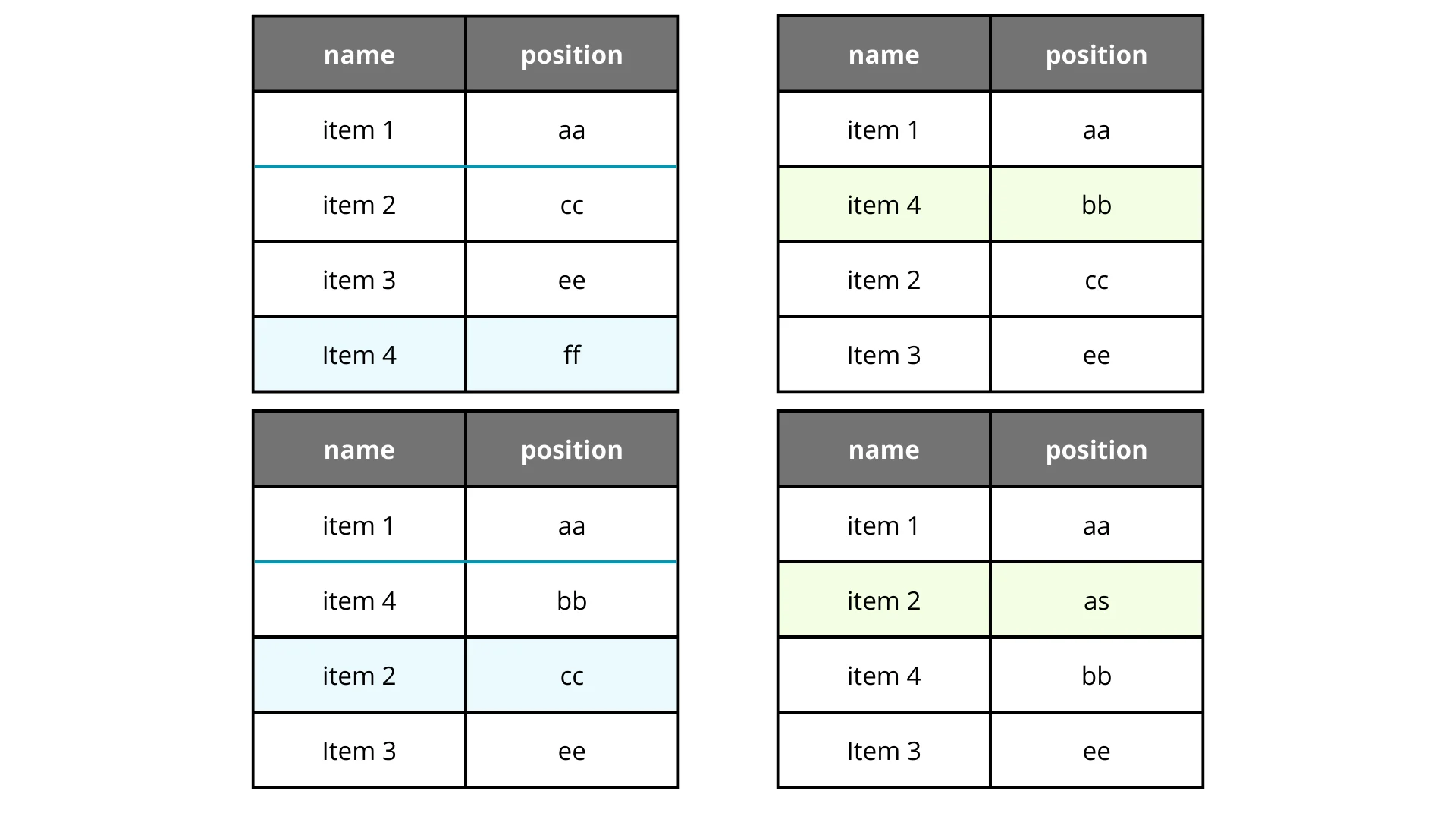
Awesome, right? By adding characters, we create practically infinite gaps. But practically isn’t theoretically infinite. String length can grow unwieldy. Eventually, you might hit string length limits or performance degradation.
We could rebalance the ranks periodically say, every 12 hours resetting all positions to have nice, wide gaps. This works but requires a heavy read/write batch job.
The other solution popularized by Jira is LexoRank with buckets. Buckets act as prefixes (containers) for sorted elements. When you run out of gaps in one bucket, you move items to a fresh bucket with reset ranks, seamlessly handling the rebalancing.
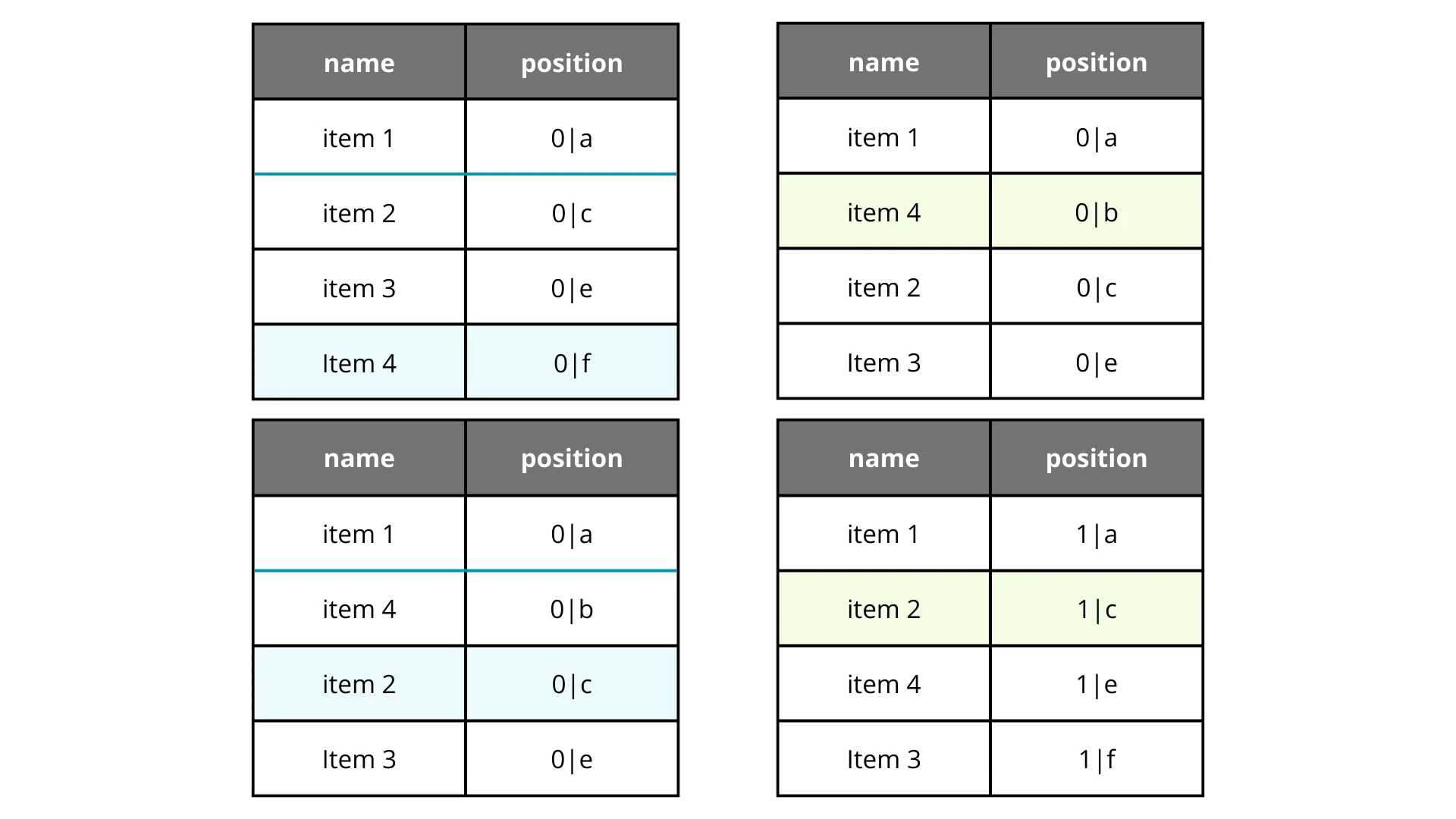
In the diagram, we start in Bucket 0. When a move forces a rank collision or minimal gap, we can migrate the involved elements (or all of them) to Bucket 1, effectively resetting the spacing without downtime.
For my project, the bucket strategy was perfect. With 6-character strings, collisions are incredibly rare. If they do happen, they only affect the specific list involved. For your project, you might mix approaches: use buckets for immediate resolution and periodic rebalancing for long-term maintenance.
The Bottom Line
We’ve covered several approaches I explored during development. There is no single “best” solution, only the one that best fits your specific constraints and use case.
If you enjoy the content, please don’t hesitate to subscribe and leave a comment! I would love to connect with you and hear your thoughts on the topics I cover.
You might also like

How to Speed Up a Heavy Web App
Discover what happened in April 2025. This month features a deep dive into optimizing heavy web apps using Web Workers, WebP, OPFS, and more.

Serverless Revolution
Discover what happened in April 2024. This month features deployment strategies using Cloudflare, Vercel, and other serverless platforms for zero-cost development.

Creating Offline-First Applications
Discover what happened in October 2024. This month features a deep dive into offline-first applications, client-server architecture, and consistency models.